We propose CTRL, a framework that trains LLMs to critique without human supervision, enabling them to supervise stronger models and achieve test-time scaling through iterative critique-revisions.
CTRL critics demonstrate two fundamental capabilities: (1) critiquing - providing iterative refinement through structured technical feedback and targeted improvement suggestions, and (2) discrimination - serving as generative reward models to evaluate and compare solution correctness.
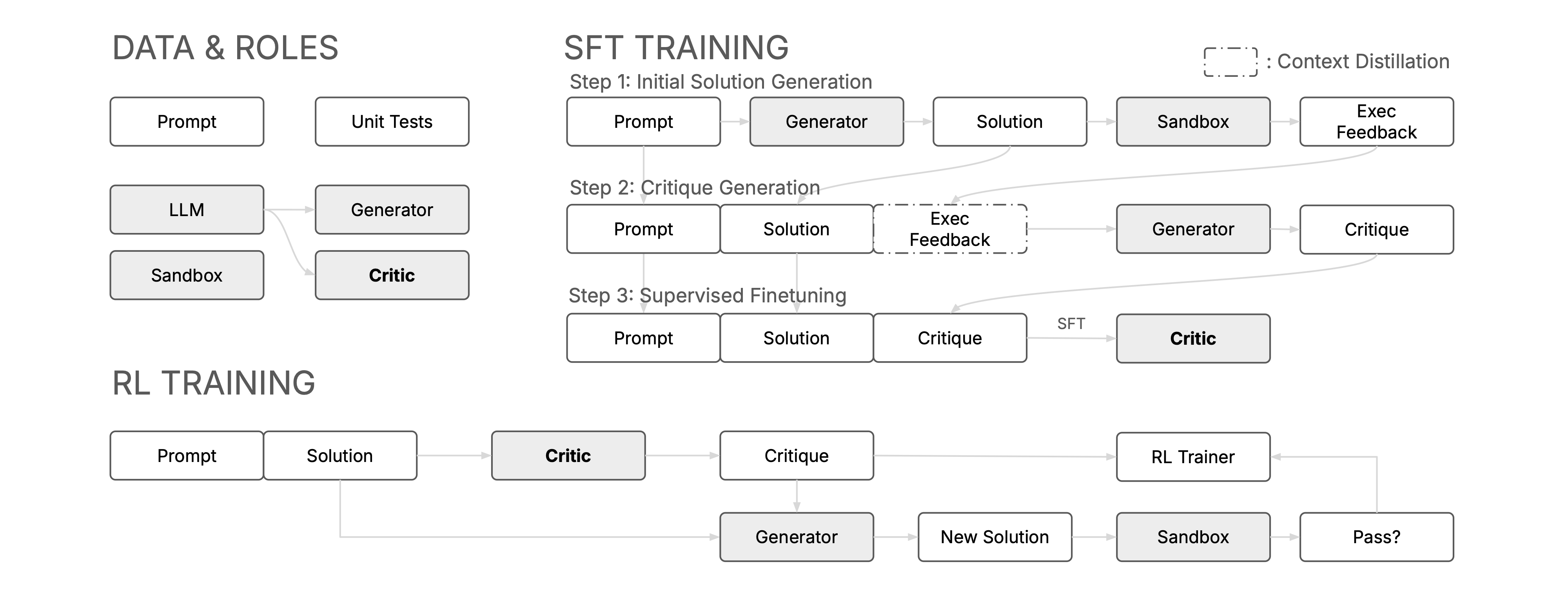
CTRL Framework
The CTRL framework is designed as a two-stage pipeline to train critic models for providing actionable feedback
and guiding iterative refinement.
Stage I: We develop an execution-guided critique synthesis approach that leverages
the model's reasoning ability over execution feedback to understand why solutions fail or succeed. Through supervised fine-tuning, the model learns to generate informative critiques that identify key issues and suggest improvements.
Stage II: We optimize critique generation through Group Relative Policy Optimization (GRPO) to maximize the probability of obtaining a correct solution after revision. GRPO reduces variance by computing group-based relative advantages and naturally focuses training on problems where high-quality critiques can drive meaningful improvements.
Key Findings
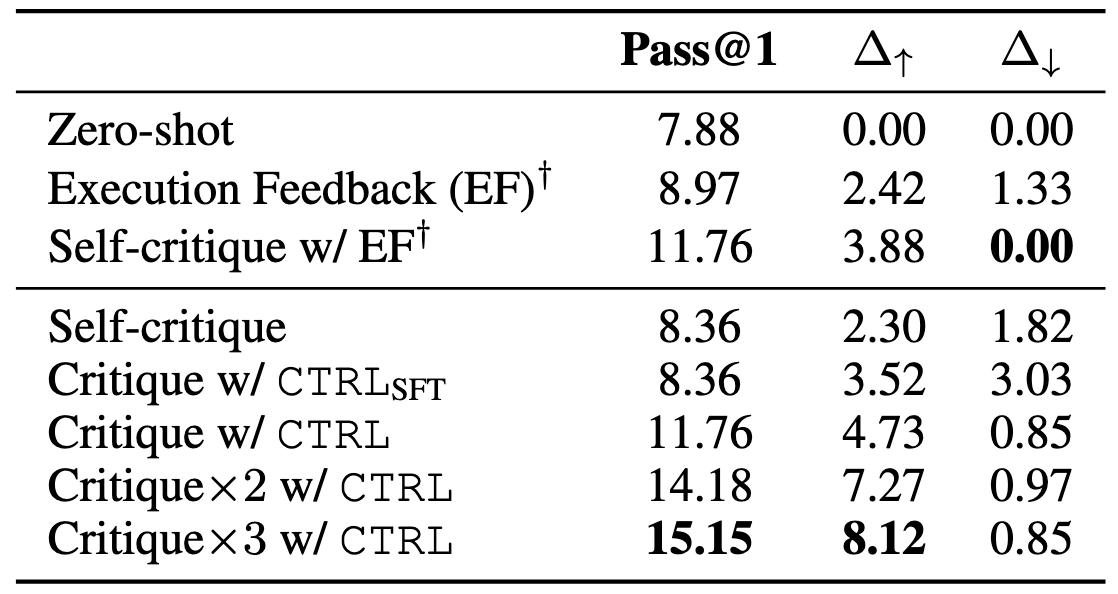
Feedback Quality Matters for Iterative Refinement
Our analysis reveals that: (1) models struggle with self-critique and raw execution feedback alone, (2) reasoning over execution feedback helps generate more accurate critiques, which grounds our execution-guided synthesis approach, and (3) trained CTRL critics achieve substantially better results by generating more accurate and targeted feedback.
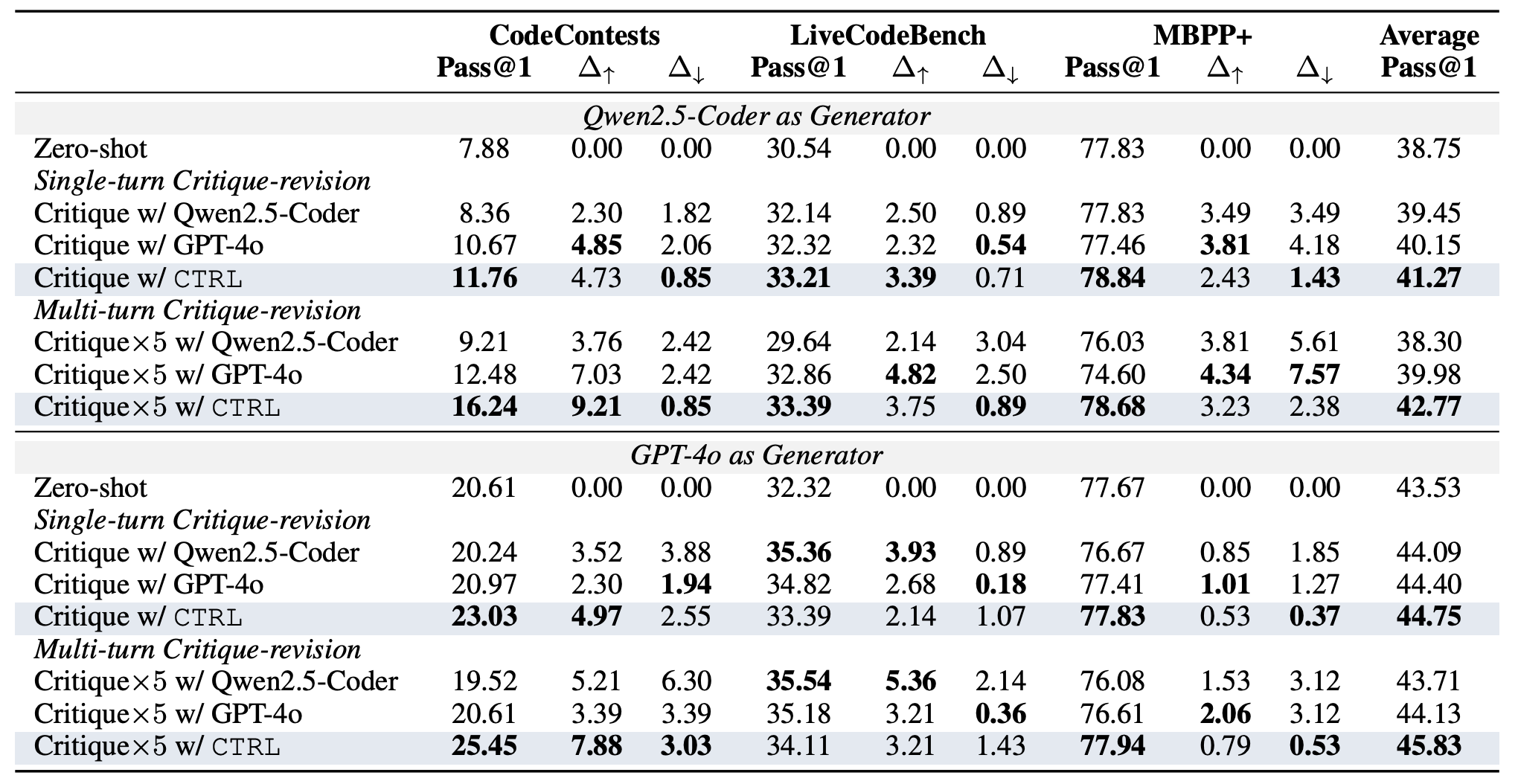
Performance on CodeContests (Pass@1 %, Δ↑: incorrect→correct, Δ↓: correct→incorrect) using Qwen2.5-Coder-32B-Ins.
×k indicates k critique-revision iterations. †Using unit tests for generation.
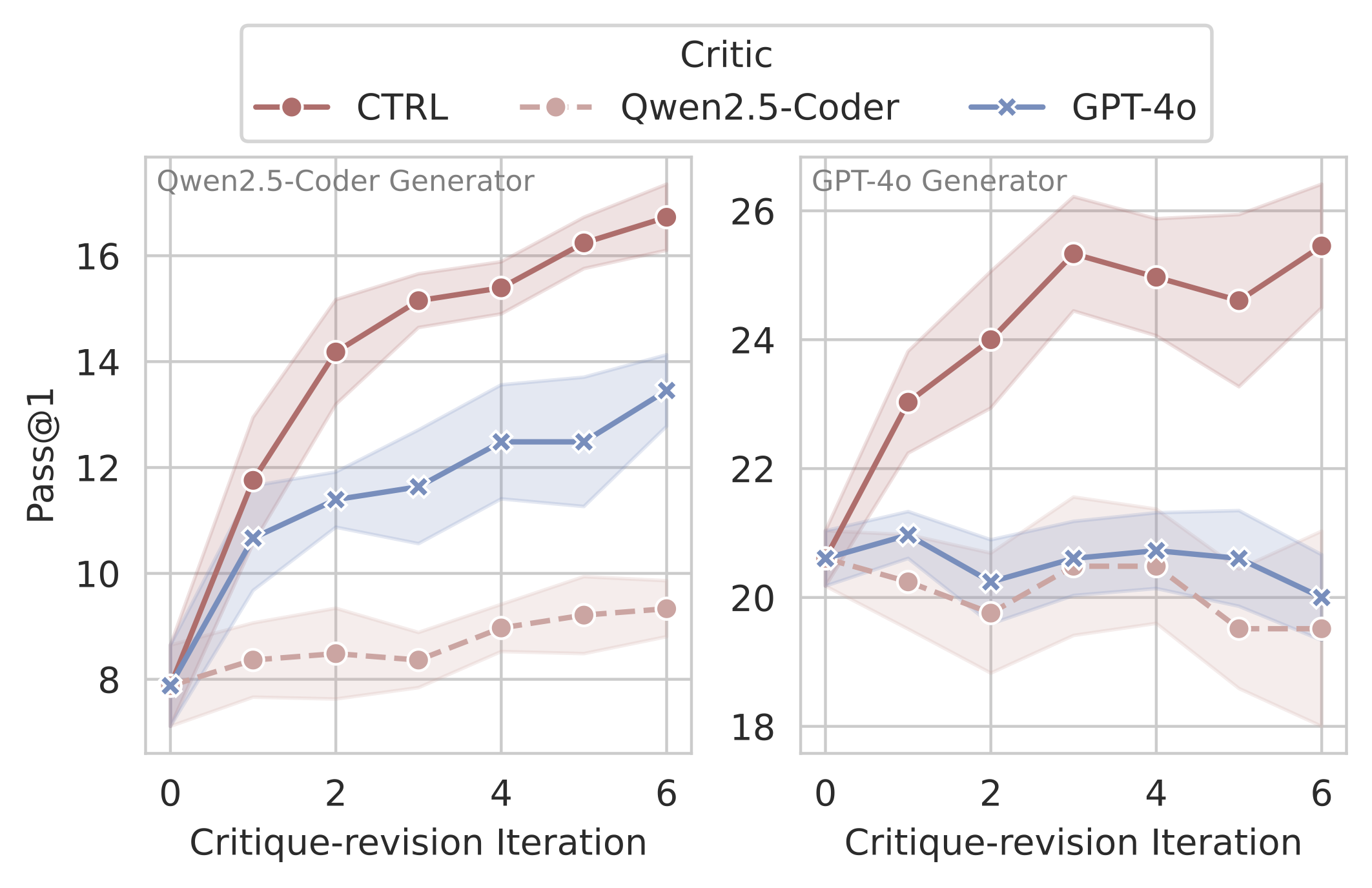
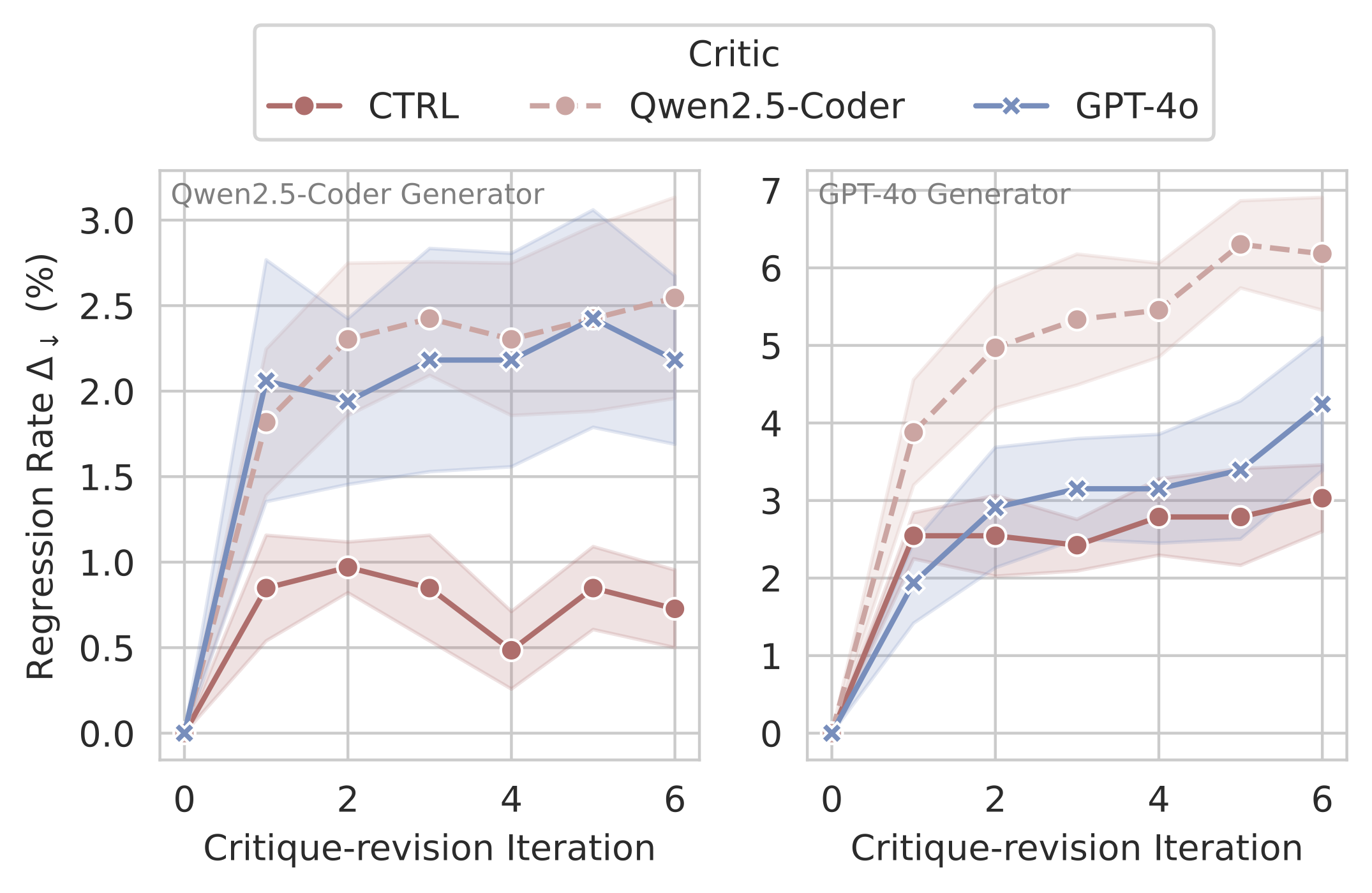
CTRL Critics Enable Test-time Scaling
Despite training only on single-turn critiquing tasks, CTRL generalizes well to multi-turn critique-revision scenarios. We observe one main advantage of CTRL is that it mitigates compounding errors by maintaining low correct→incorrect rates across iterations, while baseline models like Qwen2.5-Coder-32B-Ins and GPT-4o suffer from compounding errors during multiple revision rounds.
Pass@1 improves substantially after multi-turn iterations with CTRL critics.CTRL maintains lower correct→incorrect rates across iterations compared to baselines.
CTRL Critics Generalize Across Tasks and Models
When paired with its base model (Qwen2.5-Coder-32B-Ins), CTRL achieves a 106.1% relative improvement in Pass@1 on CodeContests through multi-turn critique-revision. The critic maintains its effectiveness when integrated with GPT-4o, improving Pass@1 by 23.5%.
CTRL consistently improves performance across different code generation tasks: CodeContests, LiveCodeBench (24.08-24.11), MBPP+; and generator models: Qwen2.5-Coder, GPT-4o.
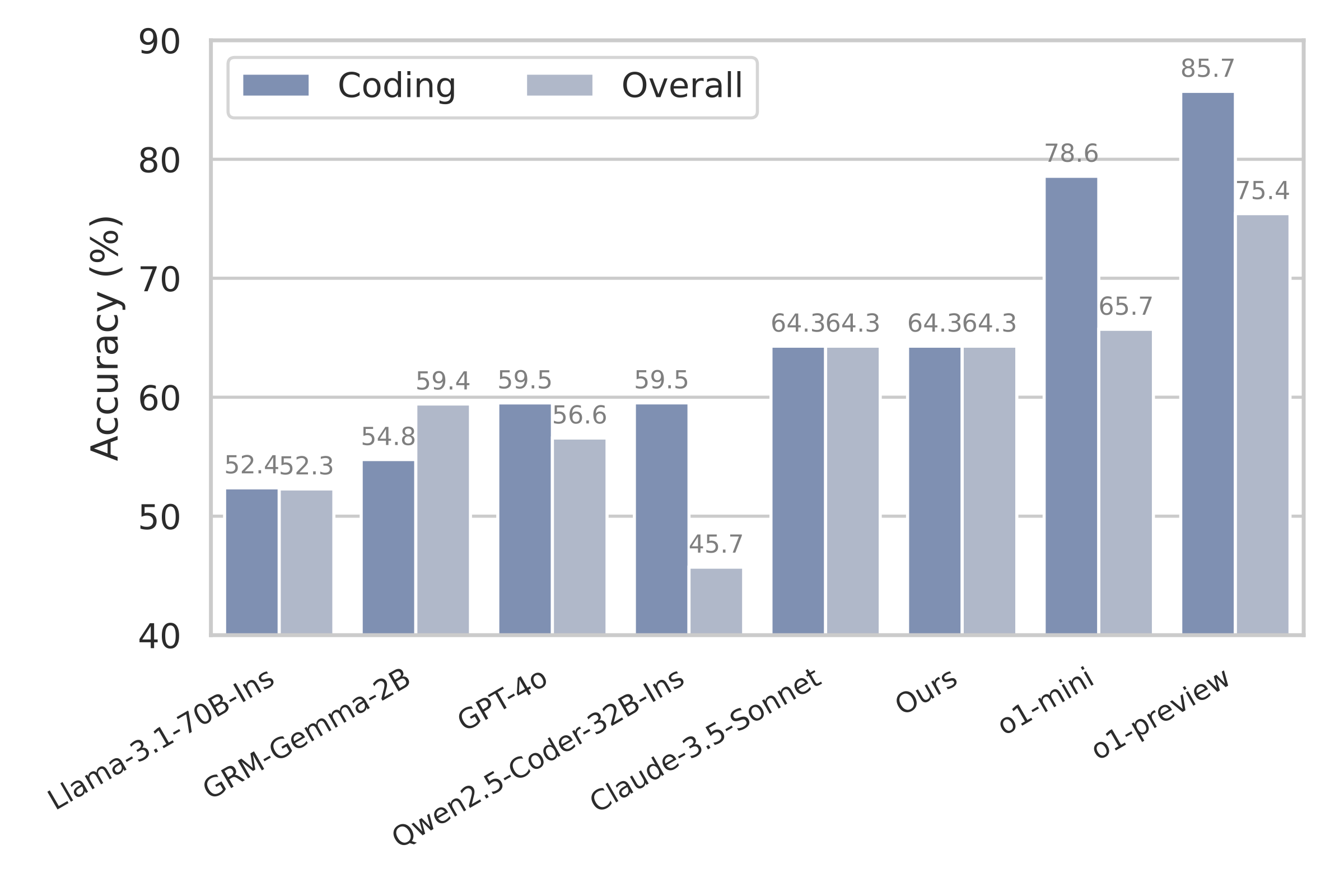
CTRL Critics Are Accurate Generative Reward Models
Our critics achieve competitive performance as generative reward models, even when evaluating outputs from more capable models (GPT-4o) across diverse domains including general knowledge, reasoning, and math. On JudgeBench, CTRL maintains comparable overall accuracy (64.3%) to stronger models like Claude-3.5-Sonnet while excelling in coding-specific evaluations. This demonstrates that unifying textual feedback enables our critics to balance discrimination and critiquing abilities effectively.
Performance comparison on JudgeBench benchmark.
Examples
Example from CodeContests
**Problem**
You had n positive integers a_1, a_2, ..., a_n arranged in a circle. For each pair of neighboring numbers (a_1 and a_2, a_2 and a_3, ..., a_{n - 1} and a_n, and a_n and a_1), you wrote down: are the numbers in the pair equal or not.
Unfortunately, you've lost a piece of paper with the array a. Moreover, you are afraid that even information about equality of neighboring elements may be inconsistent. So, you are wondering: is there any array a which is consistent with information you have about equality or non-equality of corresponding pairs?
**Solution**
```python
def can_form_array(s):
n = len(s)
# We will try to assign values to the array a
# Start with assigning 1 to the first element
a = [1] * n
# Try to assign values based on the given conditions
for i in range(n):
if s[i] == 'E':
a[(i + 1) % n] = a[i]
else:
a[(i + 1) % n] = a[i] + 1
# Check if the last and first elements are consistent with s[n-1]
if s[-1] == 'E' and a[0] != a[-1]:
return "NO"
if s[-1] == 'N' and a[0] == a[-1]:
return "NO"
return "YES"
def main():
import sys
input = sys.stdin.read().splitlines()
t = int(input[0])
results = []
for i in range(1, t + 1):
s = input[i]
results.append(can_form_array(s))
for result in results:
print(result)
if __name__ == "__main__":
main()
```
**Critique**
Analysis:
The provided solution attempts to construct an array based on the sequence of 'E' and 'N' but does not correctly handle the circular nature of the array and the constraints imposed by these characters. Specifically, the approach does not ensure consistency across the entire circular arrangement, particularly at the boundary where the last element connects back to the first.
The code assigns values to the array elements based on whether the current character is 'E' or 'N', but it does not account for potential conflicts that arise when the array wraps around. This means that the final check between the first and last elements might fail due to inconsistencies introduced earlier in the array construction process.
Improvement suggestions:
1. Consider using a more systematic approach to handle the circular nature of the array. One possible method is to use a graph traversal algorithm, treating each position in the array as a node and each 'E' or 'N' as an edge with a label indicating equality or inequality.
2. Use a union-find data structure to manage equivalence classes of indices that must hold the same value due to 'E' connections.
3. Iterate through the string and apply the rules: if 'E', ensure the indices are in the same set; if 'N', ensure they are in different sets.
4. After processing the string, verify that no conflicts exist in the union-find structure, particularly focusing on the circular connection between the first and last elements.
5. If no conflicts are found, it is possible to construct an array that satisfies the conditions; otherwise, it is not.
Overall judgment: Incorrect
Example from LiveCodeBench
**Problem**
You are given a binary string s and an integer k.
A binary string satisfies the k-constraint if either of the following conditions holds:
The number of 0's in the string is at most k.
The number of 1's in the string is at most k.
Return an integer denoting the number of substrings of s that satisfy the k-constraint.
**Solution**
```python
class Solution:
def countKConstraintSubstrings(self, s: str, k: int) -> int:
def count_substrings_with_max_char(s, max_char, k):
left = 0
count = 0
current_count = 0
result = 0
for right in range(len(s)):
if s[right] == max_char:
current_count += 1
while current_count > k:
if s[left] == max_char:
current_count -= 1
left += 1
result += right - left + 1
return result
count_0s = count_substrings_with_max_char(s, '0', k)
count_1s = count_substrings_with_max_char(s, '1', k)
return count_0s + count_1s
```
**Critique**
Analysis:
The provided solution attempts to solve the problem by counting substrings based on the maximum occurrence of '0' and '1' up to `k`, but it does not correctly account for all possible substrings that satisfy the k-constraint. The approach incorrectly calculates the intersection of substrings that satisfy both conditions without properly considering the overlap between these substrings. Additionally, the logic for counting substrings is flawed as it does not consider every possible substring of `s`; instead, it focuses on contiguous sequences of '0's and '1's up to `k`.
Improvement suggestions:
1. **Re-evaluate the Approach**: Instead of focusing on contiguous sequences of '0's and '1's, the solution should consider every possible substring of `s` and check if it satisfies the k-constraint.
2. **Iterate Over All Substrings**: Use nested loops to iterate over all possible substrings of `s`. For each substring, count the occurrences of '0' and '1' and check if either count is less than or equal to `k`.
3. **Count Valid Substrings**: Maintain a counter to keep track of how many substrings meet the k-constraint criteria.
4. **Simplify the Logic**: Consider using Python's slicing capabilities to easily extract and evaluate each substring without unnecessary checks for contiguous characters.
Overall judgment: Incorrect
Example from MBPP+
**Problem**
Write a python function to check whether every odd index contains odd numbers of a given list.
**Solution**
```python
def odd_length_sum(arr):
n = len(arr)
res = 0
# Iterate through each element in the array
for i in range(n):
# Calculate the number of subarrays in which arr[i] is present
count = ((i + 1) * (n - i) + 1) // 2
# If the count is odd, add the element to the result
if count % 2 == 1:
res += arr[i]
return res
```
**Critique**
Analysis:
The provided solution checks if the parity (odd/even nature) of the numbers at odd indices matches the index itself. This means it verifies that a number at an odd index is odd, and a number at an even index is even. However, this does not correctly address the problem at hand, which requires checking whether every odd index contains an odd number, not just matching the parity of the index.
Improvement suggestions:
1. Review the logic used in the function. Instead of checking if the parity of the number matches the parity of the index, the function should directly check if the number at each odd index is odd.
2. Consider using a more straightforward loop or list comprehension to achieve the desired result.
Overall judgment: Incorrect